


La misión de un científico de datos es la de navegar en un vasto océano de información .
Esta vez, nuestra aventura nos llevó a sumergirnos en la API de CAMMESA (Compañía Administradora del Mercado Mayorista Eléctrico), un pozo profundo lleno de datos sobre la generación y demanda de energía en Argentina. El desafío que afrontamos fue aprender a «hablar» con esta API, a pedirle exactamente lo que necesitábamos.
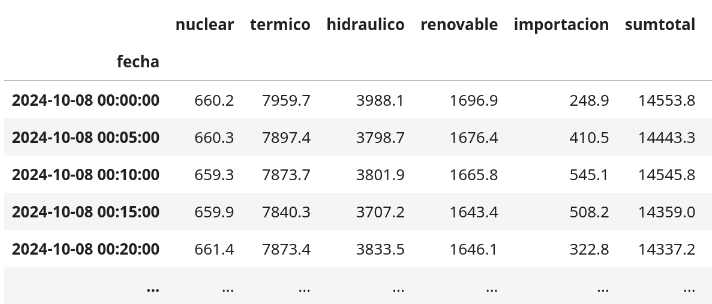
Utilizando Python, creamos un programa que podía comunicarse con la API de CAMMESA. Era como lanzar un balde al pozo y sacarlo lleno de información valiosa. Cada vez que lo hacíamos, obtuvimos datos sobre diferentes tipos de generación de energía: nuclear, térmica, hidráulica, renovable, e incluso la energía importada.
Pero estos datos, por sí solos, son piezas sueltas que necesitamos organizar para poder develar la historia. Aquí es donde entra en escena el DataFrame de pandas. Imagina una gran tabla donde cada fila representa un momento en el tiempo, y cada columna nos cuenta algo diferente sobre ese momento: cuánta energía nuclear se estaba generando, cuánta energía renovable, y así sucesivamente.
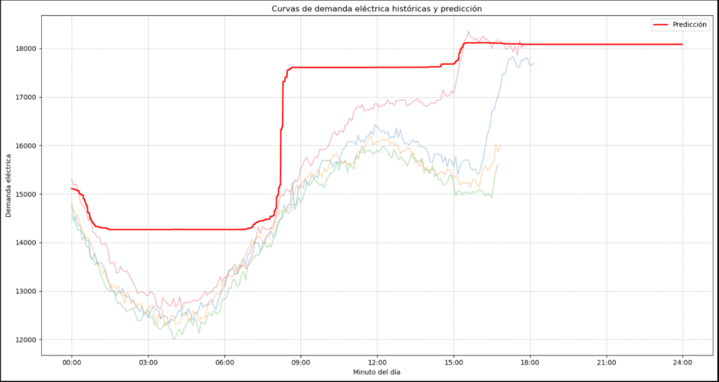
Al principio, nuestro DataFrame era un libro con pocas páginas. Teníamos datos de unos pocos días, y cuando intentamos visualizarlos, el resultado no contaba bien la historia. La curva de demanda que dibujábamos parecía una escalera irregular, con saltos bruscos de un nivel a otro. Era como intentar adivinar la forma de una montaña viendo solo unas pocas rocas.
Pero sabíamos que para ver la verdadera imagen, necesitábamos más datos. Así que volvimos a nuestro pozo de información una y otra vez. Con cada nueva adición, en nuestro libro agregamos más capítulos. La escalera irregular se fue suavizando, transformándose en una curva que revelaba patrones interesantes.
Vimos cómo la demanda de energía subía y bajaba a lo largo del día, cómo los fines de semana tenían un perfil diferente a los días laborables. Pudimos ver cómo los datos nos contaban la historia de la vida cotidiana de todo un país, traducida al lenguaje de la electricidad.
Con esta rica colección de datos en nuestras manos, estábamos listos para el siguiente paso: enseñar a una computadora a «leer» esta historia y predecir cómo continuaría. Aquí es donde entra en juego el aprendizaje automático.
Imagina que le enseñamos a nuestro barco por dónde navegar. Usamos muchos ejemplos y, poco a poco, el niño aprende a identificar las reglas subyacentes. Así funcionan los algoritmos de aprendizaje automático. Les «mostramos» nuestros datos históricos y ellos «aprenden» los patrones que rigen la demanda de energía.
Los primeros resultados no eran los mejores, demostraba que nos faltaban más datos para poder aprender mejor.
Probamos algunos de estos «aprendices digitales». Primero, el Random Forest, que es como tener un comité de expertos, cada uno mirando una parte diferente de los datos y luego votando para llegar a una predicción final. Y luego, el Gradient Boosting, un método que aprende de sus errores, mejorando sus predicciones paso a paso.
Cada uno de estos algoritmos tenía sus fortalezas y debilidades. El Random Forest era robusto y fácil de entender, las Redes Neuronales eran poderosas pero a veces un poco misteriosas en su funcionamiento, y el Gradient Boosting ofrecía un equilibrio entre precisión y velocidad.
Para evaluar qué tan bien lo estaban haciendo, usamos métricas como el Error Cuadrático Medio (una forma de medir qué tan lejos estaban nuestras predicciones de la realidad) y el coeficiente de determinación R² (que nos dice qué porcentaje de la variabilidad en la demanda podíamos explicar con nuestro modelo).
A medida que alimentábamos a nuestros algoritmos con más y más datos, vimos cómo sus predicciones mejoraban. Era como si estuvieran afinando su oído para escuchar la melodía oculta en el ruido de los datos.
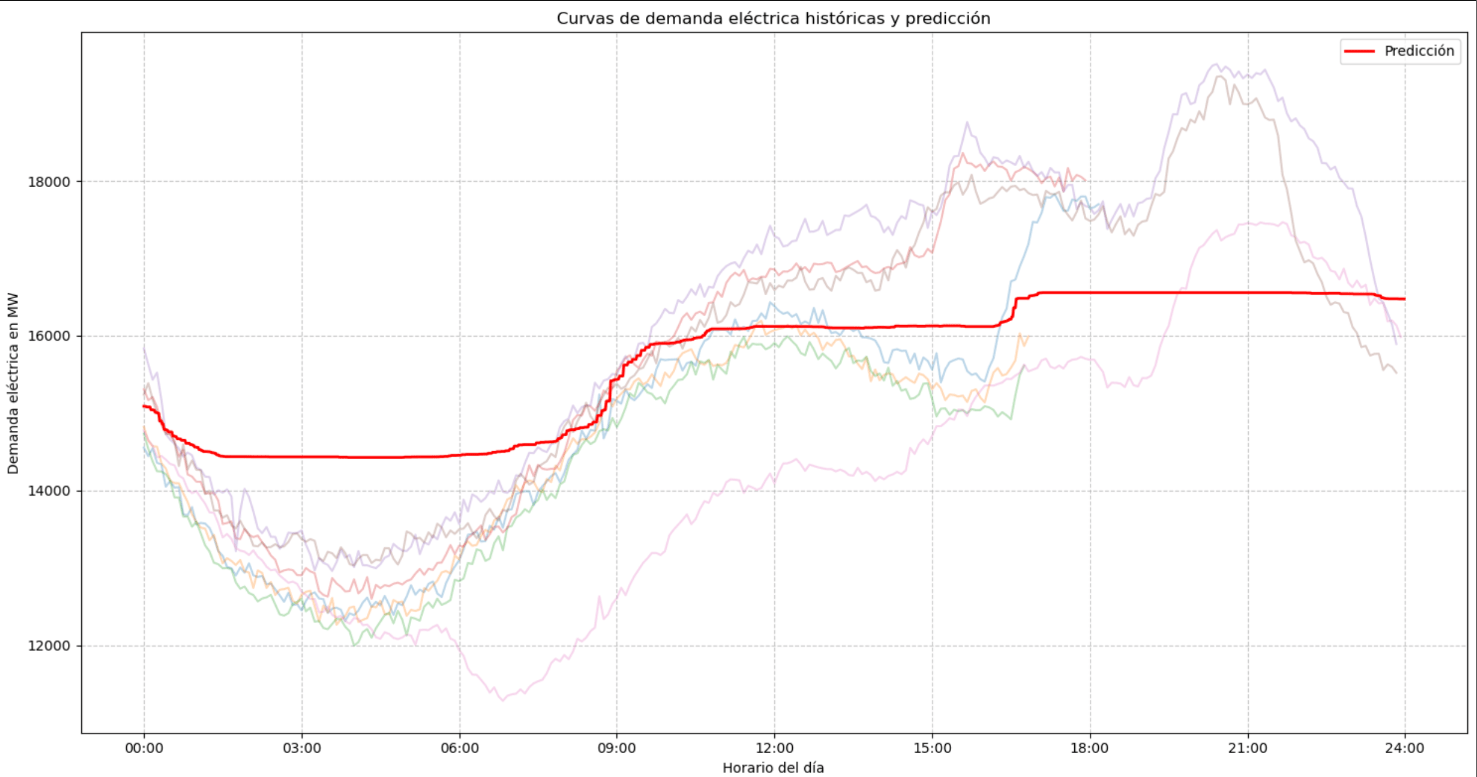
Cuando comparamos nuestra predicción con lo que realmente sucedió, fue interesante ver cuánto nos habíamos acercado. No era perfecto, por supuesto – predecir el futuro nunca lo es – pero era lo suficiente como para ver que podría ser una herramienta valiosa.
Este viaje nos enseñó muchas cosas. Aprendimos que en el mundo del aprendizaje automático, los datos son el viento que empuja las velas de nuestro barco. También aprendimos que para llegar a distintos puertos necesitamos crear rutas distintas, y que a veces el camino más simple puede ser el más efectivo.
Pero quizás la lección más importante fue esta: en cada conjunto de datos, no importa cuán árido o técnico parezca, hay una historia esperando ser contada. Y con las herramientas adecuadas – un poco de código, algunos algoritmos inteligentes, y mucha curiosidad – podemos descubrir esas historias y usarlas para dar forma a un futuro mejor y más eficiente.
Así que la próxima vez que enciendas una luz o cargues tu teléfono, recuerda: detrás de ese simple acto hay toda una red de datos, algoritmos y predicciones trabajando en armonía para asegurarse de que la energía esté allí cuando la necesites.
Así que síguenos para ver cómo evoluciona nuestro Modelo de Predicción. Y quién sabe, tal vez el próximo capítulo de esta historia lo escribamos juntos.
Pongamos en movimiento tu idea
Charlemos sobre tu idea para darle vida y potenciarla




